If you haven’t already seen it, here is the link to a free Microsoft Press ebook that highlights the new features in SQL Server 2012.
Saturday, March 17, 2012
Thursday, May 26, 2011
Few SQL Server Freebies
Here is a link to a few freebies from Quest Software I received for SQL Saturday. Registration required though.
Friday, April 30, 2010
Cloud Growth Ahead
Here is an excerpt from Steve Ballmer’s interview with InformationWeek on Microsoft’s all-in cloud computing bet and cloud adoption.
Tuesday, April 27, 2010
Infographic – Environment Impact of Computing
These are some eye-opening numbers on the impact of computing on our environment.

Sunday, April 25, 2010
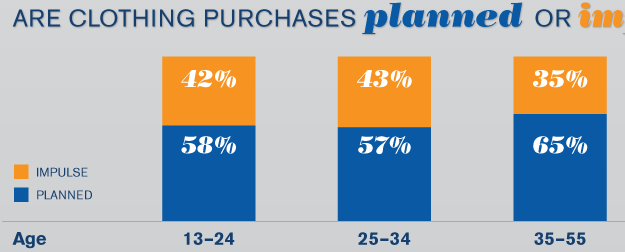
Infographic – Impulse Purchase
This fact sheet presents some interesting statistics on planned and impulse purchases.
Tuesday, April 20, 2010
Infographic, The Arty Dashboard
I just can't get enough of infographics - they are visual appealing and informative. They are designed to grab your attention, and more importantly to convey the right amount of information in a clear and concise manner. If anything, they are simply cool to look at.
I stumbled upon this one recently - it compares a few interesting stats on Blackberry and iPhone. By the way, though not actually depicted, you can gather that iPhone has a greater revenue growth rate – especially in Q4. And check out the beautiful collection from this social media firm and its thoughts on putting together an infographic.
For me infographics are very much business intelligence at work for the masses - arty dashboards if you will. I'd love to see this data visualization tool utilized within an organization - giving scorecard and metrics reporting an artistic appeal. Until there is an automation tool or some sort with pre-built and stock graphics that are customizable, I supposed it is not going to be very cost-effective to build "infographical" dashboards or reports on a regular basis.
P.S. Here are some key concepts on what makes a good information design.
Friday, March 26, 2010
Implications of Public Cloud Computing
Here is a MorningStar industry report that discusses the implications of public cloud market segment on “traditional” application software and data center business models. While this writing gears toward interests of the investment community, it offers forecast in terms of market maturity, customer adoption, profitability and vendor positions for each of service sub-segments (SaaS, PaaS and IaaS).
Friday, February 5, 2010
SQL Search
I came across a very handy tool from Red Gate called SQL Search. It allows you to find text fragments within stored procedures, functions, views and other objects in a SQL Server database. It integrates with SSMS and works with both SQL Server 2005 and 2008. Best of all, it is free and can be downloaded here http://www.red-gate.com/products/SQL_Search/index.htm .
Saturday, April 11, 2009
Documenting DI Job
 Data Integrator has a nice documentation generator which is available from the Management Console. The generator can create documentation that contains textual descriptions and graphical representations of local/global variables, work flows, data flows, and other objects as well as their relationships - even database table usage. I would love to see a similar built-in feature in SSIS. I supposed for the time-being we have to rely on 3rd-party tools or building custom code to parse the XML in .dtsx.
Data Integrator has a nice documentation generator which is available from the Management Console. The generator can create documentation that contains textual descriptions and graphical representations of local/global variables, work flows, data flows, and other objects as well as their relationships - even database table usage. I would love to see a similar built-in feature in SSIS. I supposed for the time-being we have to rely on 3rd-party tools or building custom code to parse the XML in .dtsx.

Auto Documentation provides users the ability to select the repository and job available. The documentation can be printed as either PDF or Word doc. The level of detail allowed is impressive. As I've found out it can be overwhelming if all of the options is selected for a moderately complex job - 100+ pages for a job with 70 some objects.
Sunday, December 14, 2008
Microsoft Certifications
.png)
.png) I recently sat through the 70-445 and 70-446 exams for MCTS (SQL Server 2005 BI) and MCITP (BI Developer) respectively. I took them about a week-and-a-half from each other. Even though I passed them both on my first try which I am very please, I did plan on using the free second chance promotion vouchers from Microsoft just in case.
I recently sat through the 70-445 and 70-446 exams for MCTS (SQL Server 2005 BI) and MCITP (BI Developer) respectively. I took them about a week-and-a-half from each other. Even though I passed them both on my first try which I am very please, I did plan on using the free second chance promotion vouchers from Microsoft just in case.
The MCTS Self-Paced Training Kit: Microsoft SQL Server 2005 book and its practice exams were very helpful with the 70-445 exam; I also think the book serves as a good reference in general. As you all know there is no training kit for the 70-446 exam. I believe my day-to-day experience working with the technology stack and DWBI as a whole helped a bit. I was also able to leverage my preparation with 445 for 446. In hindsight I believe I made the right decision by taking them close to each other.
The exams were about the level of difficulty I anticipated. In some ways I think 446 was a little easier than 445 - it emphasizes less on specifics and has more straight-forward question format. There were definitely quite a few questions on data mining in both exams. If I could go back and do one thing different though, I would only skim through the individual case study rather than spending the time really understanding it before embarking on the questions. The questions are applicable to only parts of the case study – read those parts when you need to. I did run out of time on a couple of case studies.
Personally I think industry certifications are great only if you have the working experience to go with them - before and after. The process of certification does promote well-rounded in-depth knowledge of the technology of interest. Real-life scenarios often take you to only those bits and pieces that are immediately relevant to solving the problems.
Friday, October 3, 2008
Contributions to KPI Library
Here are some of my recent contributions to the KPI Library - a site offering free key performance indicators and metrics submitted by the community. This collection of indicators is used in measuring efficiency, and ultimately, customer satisfaction in incident management center, help desk operation and support ticket system.
Total/Mean Time to Ticket (TTTT/MTTT)
Calculated in seconds, minutes or hours, the total or average time it takes from the reporting of an incident to the generation of the support ticket.
Total/Mean Time to Action (TTTA/MTTA)
Calculated in seconds, minutes or hours, the total or average time it takes from the creation of a support ticket to the first action taken to resolve it.
Total/Mean Time to Escalation (TTTE/MTTE)
Calculated in seconds, minutes or hours, the total or average amount of time the support ticket has been escalated through the support tiers.
Total/Mean Time to Resolution (TTTR/MTTR)
Calculated in seconds, minutes or hours, the total or average time it takes from the creation of a support ticket to the resolution of the ticket or incident.
Total/Mean Time in Queue
Calculated in seconds, minutes or hours, the total or average amount of time the support ticket is not being "actively" worked on.
Total/Mean Time in Postmortem
Calculated in seconds, minutes or hours, the total or average time it takes to perform postmortem review of the support ticket after resolution.
Sunday, April 13, 2008
Dimension Security using SSAS Stored Procedure
Often time the business needs are such that the security restrictions of users change periodically due to modification of job roles, work location and/or other attributes. A solution that can accommodate addition, update and removal of users seamlessly or dynamically in SSAS is critical to reducing latency and minimizing user security maintenance. The idea of using SSAS stored procedure to enforce dimension security dynamically is rather straightforward: While all users belong to a single SSAS database role, individually, their data access is restricted based on the set of dimension members they have permission to as determined by the SSAS stored procedure dynamically.
A short time ago my team identified a requirement to refine our overall SSAS security scheme. The data available in our cubes needed to be filtered to authorized users by their sales location(s). The list of users and their authorized sales locations are maintained in a collection of M:N relational tables in one of our SQL Server databases. Our ETL refreshes these tables regularly. For simplicity, a database view is used to de-normalize the data in these tables into "user alias-to-sales location" pairs as shown in the mock-up here.
| UserAlias | SalesLocation |
| usera | United States |
| usera | Canada |
| userb | United States |
| userc | Hong Kong |
| userd | United States |
| userd | Germany |
| userd | UK |
To avoid the potential of SQL injection attacks, a SQL Server stored procedure is used to look up the data in the view. The stored procedure (listed below) takes the alias of the current user as an argument and returns the corresponding sales locations. The domain definition is stripped off for our purpose.
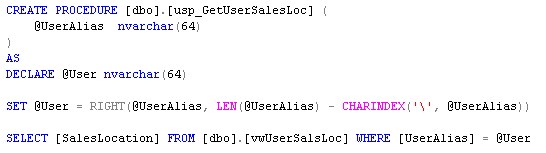
Our SSAS stored procedure (shown below) is implemented as a method from the UserSecurity C# class library - GetFilteredSet_SalesLocation(). The SSAS stored procedure employs the [usp_GetUserSalesLoc] SQL Server stored procedure to retrieve and return the unique name of the sales locations.




The GetFilteredSet_SalesLocation() method takes three string-type arguments: user alias of the current user, name of the SQL Server where [usp_GetUserSalesLoc] is located (name of the database is hard-coded in the method - yes I know), and the dimension hierarchy level. The dimension hierarchy level specification allows us to uniformly leverage the SSAS stored procedure across multiple SSAS databases and cubes with similar security filtering requirement but different dimensional schemas. The method then enumerates through the data set returned by [usp_GetUserSalesLoc] and assembles the MDX set as an output string as such:
{[Dimension].[Hierarchy].[Level].&[MemberName], [Dimension].[Hierarchy].[Level].&[MemberName], [Dimension].[Hierarchy].[Level].&[MemberName], ...}
Subsequently the SSAS stored procedure is compiled into a .NET assembly (SSASSecurity.dll) and deployed to the SSAS server. I usually place the DLL in Drive:\Program Files\Microsoft SQL Server\MSSQL.#\OLAP\bin\ directory. In this particular instance, I had the assembly registered within the server scope so that it can be used by any of the databases on the SSAS server. It can certainly be registered within the database scope.

Note that the assembly must be registered with "External access" permission at the minimum in order for the GetFilteredSet_SalesLocation() method to function properly. It also needs to run under an account that has permission to execute the [usp_GetUserSalesLoc] SQL Server stored procedure wherever it might be located.
Finally we specified one SSAS database role with all user logins added to the membership collection. The user members have read access to the cubes and dimensions. For the dimension hierarchy of interest, we placed a call to the GetFilteredSet_SalesLocation() SSAS stored procedure in the MDX expression of the Allowed member set. The STRTOSET MDX function converts the output string into a valid MDX set. The USERNAME MDX function returns the login alias of the current user.

The allowed member set can be defined for either database or cube dimension. If a dimension is referenced by a number of cubes in the database, it might be desirable to define the allowed member set at database-level and propagate the filter to cube-level through inheritance. By enabling the "Visual Total" option, we excluded the denied members from contributing to the aggregate values.
This is it. Users are now restricted to cube data for those sales locations they are authorized to see. This security scheme works nicely with Excel when the workbook data connections are specified with integrated security.
There are few approaches to implement dynamic dimension security in SSAS - as you will find in number of writings both online and offline. I found the SSAS stored procedure approach to be the most straightforward of them all and the least pervasive to implement. Furthermore security restrictions are much more immediate because they are queried directly from the relational database each time. However, we do need to ensure the SQL Server and the database where the [usp_GetUserSalesLoc] stored procedure resides is up and running at all time..
Monday, March 17, 2008
Data Warehouse Upgrade
This recent article from Intelligent Enterprise presents the roadmap of upgrading legacy data warehouses in an effort to increase flexibility, decrease data latency and deliver finer grains. The discussion makes a case for Kimball's dimensional bus architecture over the hub-and-spoke design. A good read for those who are looking to improve or extend existing DW implementations.
Sunday, February 3, 2008
BI Wish List
The authors of this recent article from Business Intelligence Network talk about their wish list of DWBI capabilities and features for the coming year or future. I simply couldn’t agree more; I almost had tears in my eyes when I was reading it. Alright that might be a little dramatic. I especially enjoyed the bits on data self-service, data black market and business user ownership.
Thursday, January 24, 2008
Justifying The Value of OLAP
So I was in this meeting at a client site yesterday, we talked about the progress of their DW upgrade and the dashboard/scorecard implementation that my consulting firm is tasked to do. During our discussion, one of the IT folks, actually a contractor indicated that the current DW (SQL Server 2000) hasn't an OLAP layer, namely cubes. All user reporting needs are satisfied through the relational DW database. As part of his assessment, he is putting together a series of proof-of-concept cubes based upon the data sitting in the current DW. Everything sounded good until we got further into our meeting and the following points were made by the other participants.
- Performance with reporting is not an issue.
- All canned reports are created in Excel and are being pushed directly to the users.
- All users are "causal." There are no "power" user requirements such as more complex analysis or ad-hoc query.
- No one in-house knows anything about cubes or multi-dimensional concept.
My inclination here is to ask, at least in the back of my mind, how much value the OLAP layer provides in this scenario. I can see the POC as showcasing the potential value the OLAP layer may offer in the distance future. Other than that, we are adding a whole new layer of technology to the DW framework which requires additional skill sets and resources to support and maintain. I maybe missing a bigger picture here but I am not seeing the ROI on this endeavor.
Thursday, January 17, 2008
Describing a Data Warehouse
While I was on a sales call yesterday I found myself explaining away what a data warehouse is. Honestly I was in some way caught off guard by the question. I shouldn't have been but I guess I haven't had to do such in a while. Or maybe I thought that data warehousing has been around for "so long" I presumed everybody would somehow know about it. This is undoubtedly a bad assumption on my part.
Nonetheless it was a refreshing surprise. It is not exactly easy to answer the question of what is a data warehouse. I wanted to be "accurate" and provide a portrayal that is both "textbook" and draws from my own account over the years.
I believe the essence of a data warehouse is data consistency and non-volatility. A data warehouse is an integration of information gathered from different operational applications and other data sources used to support business analysis activities and decision-making tasks. It captures an organization’s past transactional and operational information and changes. The data in the warehouse, in most cases, is read-only. Unlike OLTP systems, the architecture (and the technologies) of a data warehouse is optimized to favor efficient data analysis and reporting.
I suppose my view of a data warehouse, in many ways, aligns with Inmon’s top-down approach. But that certainly does not preclude me from also seeing it as a collection of more subject-oriented data marts – Kimball’s bottom-up approach.
Wednesday, December 19, 2007
Management Studio and Excel
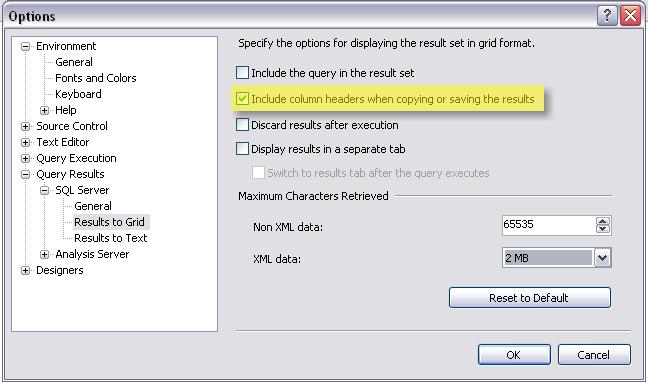
Maybe I am easily amused - but I wish I had found out about this feature sooner. SSMS has an option setting that enables copying and pasting of column headers from grid results. This comes in nifty when copying and pasting data to Excel - saving me some typing time.
Wednesday, November 21, 2007
What an Amazing Run!
 Today is a special day for me - it is my consulting team’s last day on our current project. I have been working on this OI (operation intelligence) project for more than 15 months. I do not recall being on a lengthier consulting engagement anywhere else.
Today is a special day for me - it is my consulting team’s last day on our current project. I have been working on this OI (operation intelligence) project for more than 15 months. I do not recall being on a lengthier consulting engagement anywhere else.
The project has indeed come a long way - several personnel changes, three reorganizations, and a complete management change-over. I remember we started out with the inheritance of one DW. Since then we have built and implemented a few more, and acquired a dozen more as a result of our more recent restructure. (Yes, we operate as many disparate DW's as the systems we source from.) Despite the increase in scope, we have largely maintained about the same level of resources this whole time. I guess we are managing it somehow.
Nonetheless, it has been an rewarding challenge and a great learning experience. I know what I am going to miss the most is the smart and driven people I work with.
Monday, November 19, 2007
Files in RSTempFiles Directory
Nothing beats running into a production issue starting the work week. One of our SSRS servers encountered an assembly loading error early this morning – making the reports unavailable to our users. The error was caused by the fact that the disk it is running on did not have enough space.
It happened that the volume of the content in the Program Files\Microsoft SQL Server\MSSQL.#\Reporting Services\RSTempFiles directory has grown over time and ultimately filled up the disk. Unlike SSRS logs (in the LogFiles directory), these temporary snapshots are not being cleaned up automatically. The "CleanupCycleMinutes"setting in RSReportServer.config appears to work only with storage in database – not file system.
In the interest of getting SSRS back online ASAP, we manually deleted the older snapshot files - reclaiming a decent chunk of space. Going forward, we will need to put in place a script or some sort to automatically and regularly keep the directory clean. Sounds like an action item.
It happened that the volume of the content in the Program Files\Microsoft SQL Server\MSSQL.#\Reporting Services\RSTempFiles directory has grown over time and ultimately filled up the disk. Unlike SSRS logs (in the LogFiles directory), these temporary snapshots are not being cleaned up automatically. The "CleanupCycleMinutes"
In the interest of getting SSRS back online ASAP, we manually deleted the older snapshot files - reclaiming a decent chunk of space. Going forward, we will need to put in place a script or some sort to automatically and regularly keep the directory clean. Sounds like an action item.
Tuesday, November 13, 2007
SSIS Raw File Reader
Several months ago while I was working a solution to move data across network domains, I came across this nifty utility called “Raw File Reader.” This tool allows me to read and view the data contained in raw files produced by SSIS. It is currently a freeware and more information can be found at http://sqlblogcasts.com/blogs/simons/archive/2007/01/11/SSIS-Rawfile-viewer---now-available.aspx .
Thursday, October 11, 2007
64K Limit
The Problem
I can’t believe I am still talking about SQL Server 2000 when SQL Server 2008 is coming around the corner. But here it is.
At my current project, my team and I operate a portfolio of DWBI solutions implemented on SQL Server 2000 and 2005 platforms. A couple days ago, the ETL processing of one of our older DWs (i.e. SQL Server 2000) failed out of the blue. Upon brief investigation, I determined that the failure was caused by a dimension table containing 64,400 plus member records. In Analysis Services 2000, a dimension member can’t have more than 64,000 children. This applies to the “All” member as well. Anything more, as in our case, causes the processing of the dimension to fail.
The Solution
To get around this limitation, we considered few options and their viabilities. Bear in mind that the dimension in question is a degenerated dimension derived from one of the facts in the DW.
- Reduce the total number of members going into the dimension in the cube.
- Reduce the total number of members going into the dimension in both the relational DW and the cube.
- Create a dimension hierarchy to reduce the number of children per parent – with no changes to the total number of members.
In this particular case our customers and I settled on option 2. We purged all of the fact records older than a cut-off date thereby trimming down the number of members going into the dimension. (We effectively condensed the volume of history available in the DW.)
I must admit we took the quick and dirty approach. Option 3 suggested a more elegant and longer-term solution however it is also much more involved. Furthermore the nature of the data does not allow us to build a dimension hierarchy with meaningful or other logical groupings (Rolodex-style breakdown). As far as option 1 is concerned, since we preferred the data modifications to be consistent in both relational DW and OLAP tiers, the option is out.
The Lesson
I do feel that running into this limitation forces our customers and my development team to re-evaluate the business needs, growth requirements and usability of the DWBI solution. A few thousand children per parent already present a usability problem – that’s a lot of rows for users to drill down into a dimension. I simply can’t imagine having 64,000 items to select from in a drop-down list. Moreover some client tools may not be able to handle the volume gracefully.
Saturday, September 29, 2007
The Source is Ready
On a number of occasions, our ETL applications needed to determine whether a SQL Server database has come back online after being restored from a backup. Such requirement arises when the systems we are sourcing from create copy of their data and restore it onto a separate server dedicated to all downstream consumption. These source systems are often mission-critical or LOB applications that restrict direct ETL operations - fearing performance impact on user queries.
A quick and simple way to find out the availability of a SQL Server database is to use the DATABASEPROPERTYEX function. This T-SQL function returns the current setting of the specified database option or property for the specified database. The SQL is listed below.
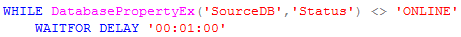
The WHILE loop checks to see if the "status" of the "SourceDB" database is online and available for query, if not, it waits for a minute then checks again.
To maximize reusability and uniformity of our ETL implementation, we wraps this piece of code in its own separate SSIS or DTS package. The package in turn can be executed as first step of a job or within another package.
Wednesday, September 12, 2007
SSIS Configuration File for Manageability
Using SSIS configuration file (.dtsConfig) to manage environment variables, such as server connections and source file paths, can contribute greatly to portability and manageability of an ETL application that comprised of SSIS packages.
We utilize configuration files extensively in our DWBI implementations to alleviate the complexity of promoting builds (DEV, TEST, PROD), server migration and deployment to multiple ETL servers. SSIS solutions can be readily deployed to different environments with simple changes to these XML-based configuration files without having to modify a single package.
For instance, one of our DWBI implementations employs 2 separate servers to "load balance" the processing of flat files (web logs) made available on a central file server. The same SSIS solution is deployed on these 2 ETL/staging servers (SQL Server, SQL Server Agent, Integration Services). But the solution instances are driven by slightly different configuration file specifications. Below is the over-simplified data flow.
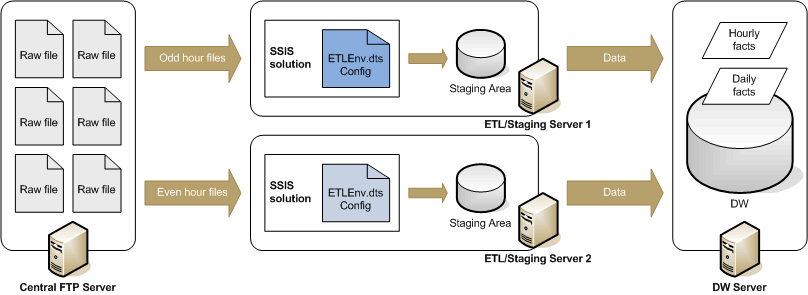
The configuration file on each server specified the same source file server, destination DW server, and other control variables with the exception of one flag to indicate whether to process odd- or even- hour source files and another to indicate which one of the 2 target ETL servers to stage the extracted data.
Thursday, September 6, 2007
 Please.
Please.Sunday, August 12, 2007
SSAS Database Synchronization for Scalability & Availability
Database synchronization can be leveraged as a convenient solution to promote scalability and availability for the OLAP tier in a DWBI implementation. It allows for a scale-out strategy by deploying copy of the SSAS database to multiple servers to load-balance user queries. It increases availability by reducing the duration of time the SSAS database is offline or inaccessible due to processing. In many scenarios, synchronization takes less time to perform than processing.
Traditionally, in Analysis Services 2000, synchronization implies backing up and restoring the SSAS database. Nonetheless I had mixed success of getting msmdarch.exe to work properly with larger .cab files and across servers. Analysis Services 2005 simplifies the task of synchronizing SSAS databases by making available the Synchronize XMLA command and the Synchronize Database Wizard which is a UI that ultimately creates and issues the Synchronize XMLA command. Of course, in 2005, we can still back up and restore the .abf file. But the synchronization capability is much more straight-forward.
Several of our DWBI implementations take advantage of this synchronization capability Analysis Services 2005 has to offer. Our solution performs processing of the cubes on a staging SSAS server and deploys (or sync's) the cubes to the presentation SSAS servers dedicated for user queries. The diagram below illustrates the processing-flow of our solution.
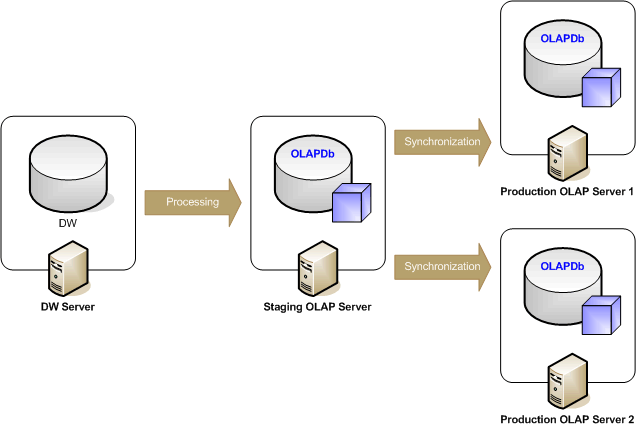
Synchronization to the production SSAS servers is achieved by the means of the Synchronize XMLA command. A DDL script in the form of XML specifies the command and all of its parameter elements (i.e. Source database, compression option) in an .xmla file. (XMLA provides a declarative approach to specifying requirement and effectively eliminates the need of writing more complicated code - consequently enhancing the maintainability of the solution.)
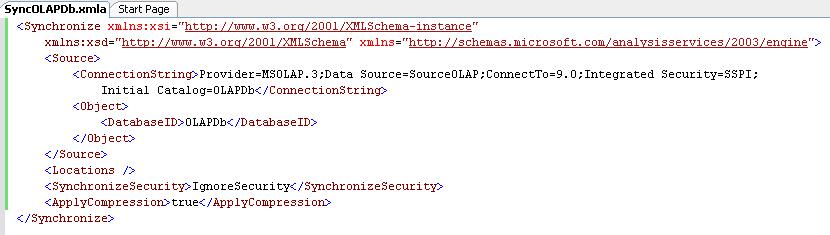
The Synchronize XMLA command is to be issued on the target SSAS server as opposed to the source SSAS server. It can be manually executed in SSMS. Or it can be run programmatically as in our solution using the Analysis Services Execute DDL task in a SSIS package.
In order for the Synchronize command to work successfully, make sure that the Windows account under which the target SSAS server runs has administrative rights to the source database. The target server executes the Synchronize command under its service account.
Sunday, July 29, 2007
Let's Get Started
Welcome
Hi Everyone. Welcome to my first post on this newly launched blog of mine. I'll be updating this blog regularly with my real-life day-to-day experience working in the vast and exciting world of data warehousing and business intelligence (DWBI).
As an IT professional, I have worn many different hats over the years – salesman, manager, architect, developer, analyst, support and user. Though DWBI hasn't been the only thing I’ve done, it is certainly one of the most challenging and exciting expertise IMHO.
By no means will I try to come across as all-knowing DWBI guru. Because I am not. (And I have not met one yet.) Nonetheless I am definitely not new to the field. Here I am simply hoping to share some of my experience – good ones and bad ones. I might rant a little bit too.
Why the blog?
I literally woke up one day about a month ago and said, “I should start a journal like this. It would be fun. I think this would be a great medium to share and learn.”
I still remember hating writing as a kid. The only time I’ve actually written a journal was when I was backpacking in Europe right after I graduated from college. The experience was of such great immensity that I had trouble putting it on paper.
Hi Everyone. Welcome to my first post on this newly launched blog of mine. I'll be updating this blog regularly with my real-life day-to-day experience working in the vast and exciting world of data warehousing and business intelligence (DWBI).
As an IT professional, I have worn many different hats over the years – salesman, manager, architect, developer, analyst, support and user. Though DWBI hasn't been the only thing I’ve done, it is certainly one of the most challenging and exciting expertise IMHO.
By no means will I try to come across as all-knowing DWBI guru. Because I am not. (And I have not met one yet.) Nonetheless I am definitely not new to the field. Here I am simply hoping to share some of my experience – good ones and bad ones. I might rant a little bit too.
Why the blog?
I literally woke up one day about a month ago and said, “I should start a journal like this. It would be fun. I think this would be a great medium to share and learn.”
I still remember hating writing as a kid. The only time I’ve actually written a journal was when I was backpacking in Europe right after I graduated from college. The experience was of such great immensity that I had trouble putting it on paper.
Subscribe to:
Posts (Atom)



.png "Business Intelligence Developer")
.png "SQL Server 2005 Business Intelligence")

